Dokumentation
Table of Content
Herzlich Willkommen im Flowy-Dokumentationsbereich! Hier finden Sie eine Fülle von Informationen und Ressourcen, die Ihnen helfen, das Beste aus der Flowy-Plattform herauszuholen. Egal, ob Sie gerade erst mit Flowy anfangen oder ein erfahrener Benutzer sind, Sie finden alles, was Sie über den Aufbau, die Bereitstellung und Verwaltung von Workflow-Automatisierungslösungen mit Flowy wissen müssen.
Aufgrund der Größe wurde die Dokumentation in separate Dokumente aufgeteilt:
- Einführung
- Installation
- Plug-in: erläutert, wie eigene Plug-ins entwickelt werden können
- Berechtigungen: beschreibt das interne Berechtigungssystem
- Prozesse: Anleitung zur Erstellung von Workflows (innerhalb von Flowy)
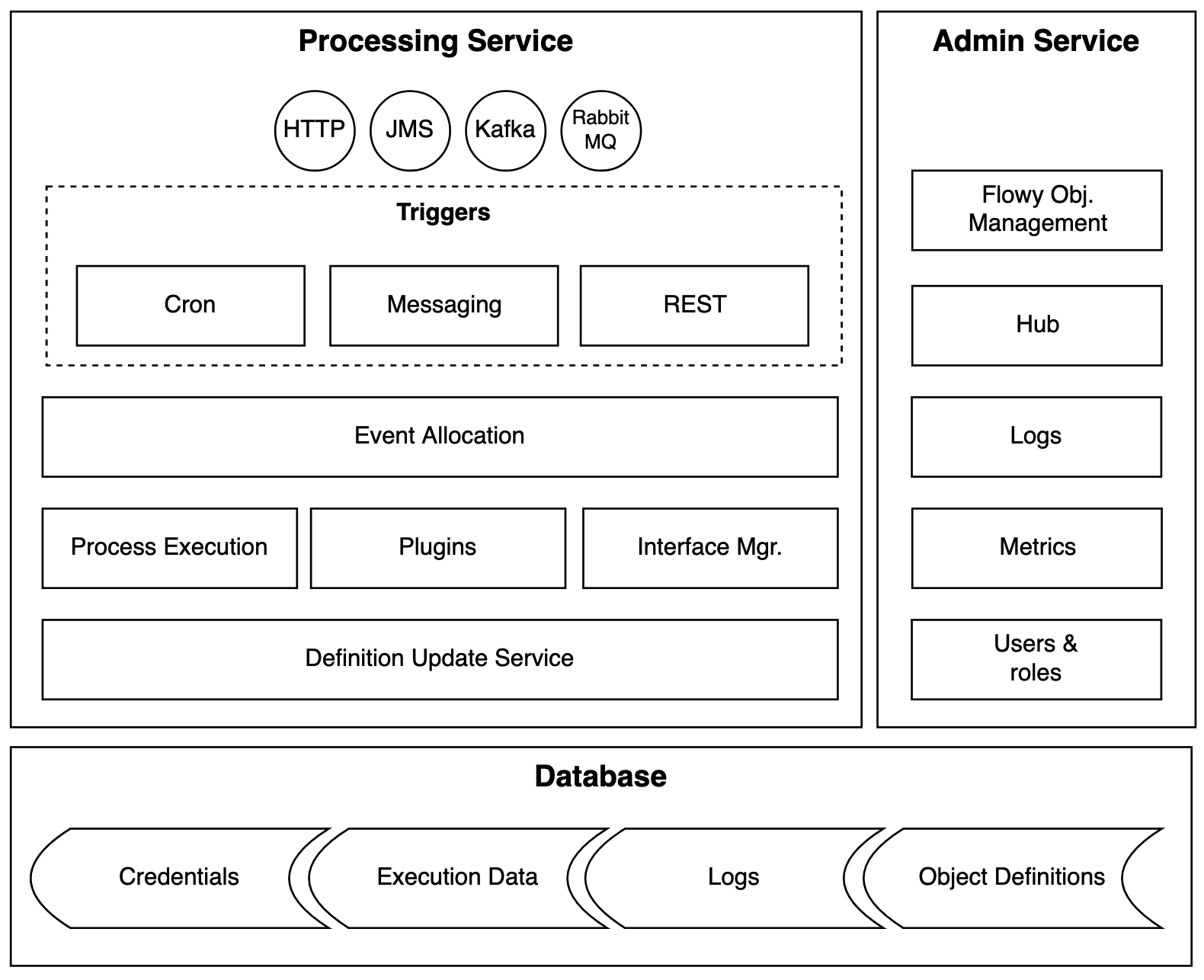
- Dienste: Informationen über die Flowy-Dienste
- Schritte: liefert Details zu den Schritten
- Trigger: liefert Details zu den Triggern, die Prozesse starten
- Zugangsdaten: erfahren Sie wie Flowy Zugangsdaten verwaltet
- Objekte: gibt Einblicke in die interne Struktur und Arbeitsweise
- Vorlagen & Übersetzungen: erläutert, wie Vorlagen und Übersetzungen genutzt werden können
- Validierungen: erklärt, wie die Integrität der Daten, die in das System fließen, sichergestellt werden können
- Konfiguration: dokumentiert, wie Flowy konfiguriert wird
- Start: gibt Anleitung zur korrekten Inbetriebnahme von Flowy
- Docker: beschreibt, wie Docker-Images erstellt und benutzt werden
- Einrichtung auf AWS mit EC2: bietet eine Anleitung zur Einrichtung von Flowy mit AWS und EC2-Instanzen
- Authentifizierung für Flowy Prozesse: erläutert, wie man sich anmeldet, um authentifizierte Flowy-Prozesse auszulösen
- Flowy Util: CLI-Tool für eine einfache und effiziente Integration in die CI- und CD-Automatisierung
- Fehlerbehebung: bietet Hilfe, falls Probleme auftreten
- Versionskontrolle: Details dazu, wie Flowy die Versionskontrolle handhabt
- Limitierungen: gibt einen Überblick über die Einschränkungen von Flowy
- Begriffsdefinitionen: eine Übersicht über die Begriffe, die auf dieser Seite verwendet werden
Einführung
Plattformübersicht
Flowy ist eine Plattform, die darauf ausgelegt ist, hoch skalierbar und zuverlässig zu sein. Sie wurde nach den Prinzipien der hexagonalen Architektur entworfen und trennt klar zwischen der Benutzerseite, der Geschäftslogik und der Serverseite.
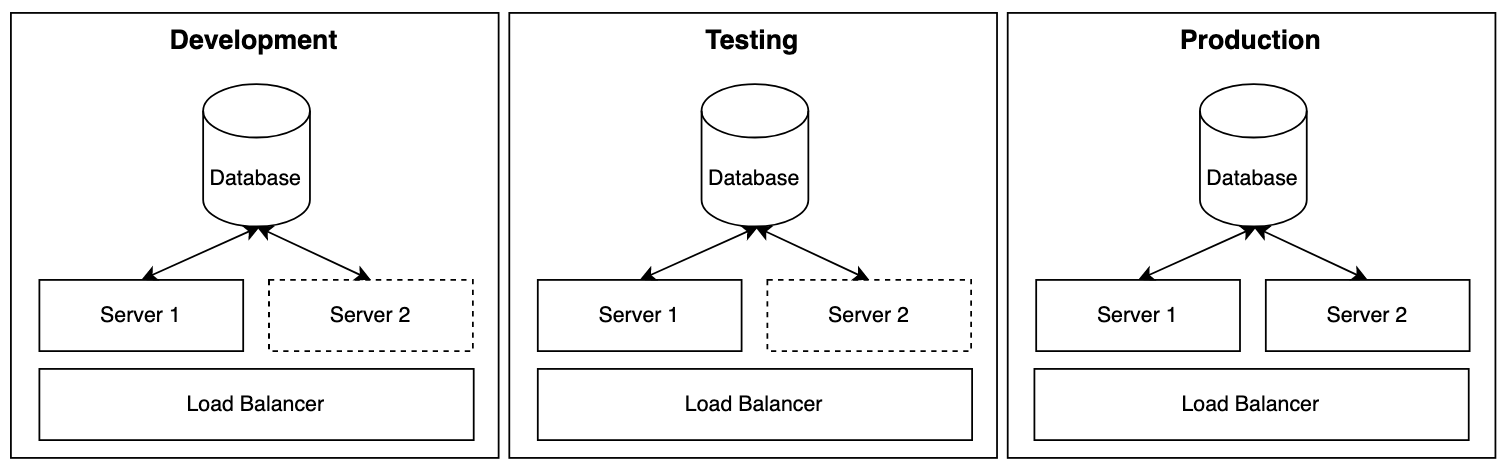
Flowy wird unter Nutzung von 3 Umgebungstypen betrieben:
Event-gesteuerte Workflows in Flowy
Jede Anforderung wird entweder durch eine Benutzerinteraktion (z.B. über eine REST-Anfrage) oder durch einen automatischen Trigger (z.B. durch eine zeitbasierte Bedingung) ausgelöst. In beiden Fällen wird ein Ereignis erstellt und später entsprechend der vordefinierten Geschäftslogik verarbeitet.
Im Kern besteht jeder Prozess innerhalb von Flowy aus folgenden Elementen:
- Trigger: die Auslösebedingung. Kann z.B. eine Aktion eines Benutzers oder eine zeitgesteuerte Automatisierung (z.B. jeden Mitternacht) sein.
- Ereignis: Sobald ein Trigger ausgelöst wurde, wird ein Ereigniseintrag erstellt, der zur Verfolgung seiner Verarbeitung verwendet wird.
- Prozess: Dies ist die Logik und das Verhalten, das Aktionen auslöst und basierend auf deren Ergebnissen reagiert.
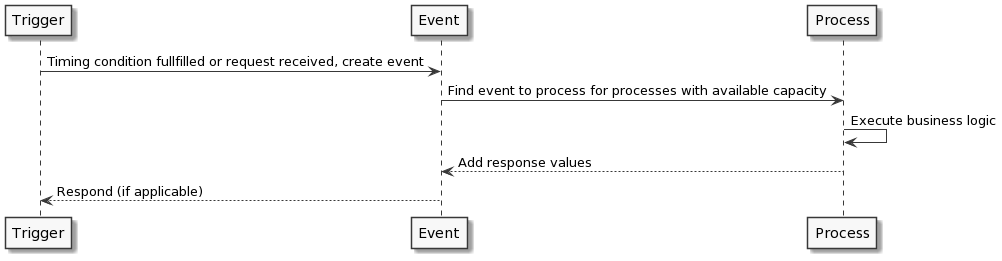
Jeder Prozess ist eine Abfolge von Schritten, einschließlich Skripting, bedingter Logik, Unterprozess-Ausführung und Datenbankinteraktion.
Flowy-Prozesse werden immer auf dem Verarbeitungsdienst ausgeführt, der im Abschnitt Dienste beschrieben wird. Um mehr über die Prozesse zu erfahren, lesen Sie bitte Flowy Prozesse und für Informationen über die Schritte, die sie enthalten, Flowy Schritte.
Flowy Prozesse
Jeder Prozess in Flowy stellt einen modularen, deterministischen Workflow dar, der auf Eingaben reagiert und Daten durch klar definierte Schritte transformiert. Ein Prozess besteht aus einer Abfolge von Operationen, einschließlich Skripting, bedingter Logik, Unterprozess-Ausführung und Interaktionen mit externen Systemen.
Auf hoher Ebene verhält sich ein Flowy-Prozess wie eine leichtgewichtige Zustandsmaschine:
- Er wird durch ein externes Ereignis ausgelöst (wie z.B. eine REST-API-Anfrage)
- Er arbeitet mit einem gemeinsamen Variablenkontext namens Process Cache, wobei Variablen mit $ vorangestellt werden
- Er führt typisierte Schritte aus, jeder mit einem klar definierten Zweck—Daten transformieren, auf Datenbanken zugreifen oder Fehler behandeln
- Er schreitet durch bedingte Pfade, Unterprozess-Aufrufe oder Iterationen bis zur Vollendung voran
Jeder Prozess ist so konzipiert, dass er von außen betrachtet zustandslos ist. Sein Zustand wird vollständig durch den Variablen-Cache gekapselt und durch Schritt-Logs persistiert, was Debugging und Wiederherstellung sowohl deterministisch als auch nachverfolgbar macht.
Designprinzipien:
- Prozesse klein und komponierbar halten
- Logik als klaren Fluss strukturieren: Eingaben → Transformation → Ausgaben
- Prozesskomposition für Wiederverwendbarkeit und Trennung von Belangen nutzen
Flowy ist darauf ausgelegt, modulares Design zu fördern. Anstatt Logik über Prozesse hinweg zu duplizieren, können Sie wiederverwendbare Muster definieren, die Wartbarkeit und Testbarkeit verbessern. Kapseln Sie häufig verwendete Logik—wie die Validierung von Unternehmen, die Erstellung von Audit-Logs oder die Vorbereitung von Übersetzungen—in dedizierten Unterprozessen und rufen Sie diese über den Execute Process-Schritt auf. Dies macht Ihren Hauptprozess leichter lesbar und hält die Logik isoliert.
Nutzen Sie die integrierten Templates- und Translations-Objekte, um UI-Inhalte oder lokalisierte Nachrichten zu externalisieren. Dies ermöglicht es Ihnen:
- Nachrichten auszutauschen, ohne die Geschäftslogik zu berühren
- Konsistente Formatierung über Schritte hinweg wiederzuverwenden
Anstatt URLs oder Zugangsdaten fest zu codieren, definieren Sie diese zentral mit:
- Einstellungen: für umgebungsspezifische Werte
- Anmeldedaten: für API-Schlüssel, Datenbankzugriff und andere sensible Daten
Variablen und Prozess-Cache
Variablen können verwendet werden, um Daten während der Laufzeit temporär zu speichern. Eine Variable kann in Flowy durch $. gefolgt vom Variablennamen deklariert werden.
Während der Ausführung werden Variablen im Speicher in dem sogenannten Prozess-Cache gespeichert. Standardmäßig wird der Cache als Teil jedes Schritt-Logs in der Datenbank gespeichert. Dieses Verhalten kann deaktiviert werden, um die Leistung zu verbessern und die Größe der Datenbank zu reduzieren.
Die Variablen können zur Laufzeit manipuliert oder sogar entfernt werden (durch den Schritt "Variablen löschen"). Der Cache ist für alle Schritte eines Prozesses vollständig zugänglich.
Variablen, die voraussichtlich Dateien enthalten (d. h. verarbeitet über FTP, IMAP, Image, PDF, S3 oder ZIP), werden nicht persistiert; für diese zeigt der Cache lediglich deren Größe an.
Aus Sicherheitsgründen sollten Variablen nicht für sicherheitsrelevante Daten verwendet werden. In solchen Fällen wird die Verwendung von Anmeldedaten empfohlen.
Information
Java setzt eine Grenze für die maximale Größe von Daten, die in einer Variablen gespeichert werden können. Diese Grenze hängt von der Umgebung und dem verfügbaren Heap-Speicher ab. Aufgrund unserer Erfahrung empfehlen wir, Variablengrößen unter 15 MB zu halten, um eine optimale Leistung und Stabilität zu gewährleisten.
Es ist zu beachten, dass das System zur Laufzeit automatisch Ausführungsparameter in die Variable $.flowy einfügt.
Entwicklungsansatz
ie typische Entwicklung muss in folgender Reihenfolge erfolgen:
- Beginnen Sie mit der Erstellung eines Prozesses: Es genügt, zuerst nur einen kleinen Teil der späteren Funktionalität zu implementieren.
- Erstellung von Triggern: Zum Testen ist es praktisch, einen Cron-Trigger zu erstellen und ihn bei Bedarf manuell auszulösen. Alternativ kann ein REST-Trigger erstellt und durch curl, Insomnia REST, Postman oder ähnliche Tools ausgelöst werden.
- Erstellung von Anmeldedaten, Vorlagen, Übersetzungen und Validierungen sowie der erforderlichen Updates von Triggern und Prozessen.
Dieser bewusst iterative Ansatz führt schnell zu verwendbaren Ergebnissen.
Es gibt eine klare Trennlinie zwischen Konfigurationsdaten und Geschäftslogik. Dadurch wird die effektive Übertragung von Workflows durch Umgebungen (z.B. Entwicklung, Test, Produktion) ermöglicht. Dabei werden sie getestet. Wenn sie die Produktion erreichen, haben Sie sowohl den Workflow selbst als auch die Fähigkeit zum Bereitstellen sowie die Supportprozesse getestet.
Zu den Konfigurationsdaten gehören die folgenden Objekttypen:
- Anmeldedaten
- Einstellungen
- Übersetzungen
- Validierungen
Die Geschäftslogik wird mit den folgenden Objekttypen implementiert:
- Bibliotheken
- Entität
- Module
- Plugins
- Prozess
- Trigger
- Vorlagen
Dieser Ansatz erleichtert das Rollout vorhandener Workflows in neue Umgebungen, da es nur eine Frage der Konfiguration ist.
Versionskontrolle
Flowy bietet native Unterstützung für Versionierung und stellt sicher, dass Benutzer verschiedene Versionen ihrer Projekte leicht verwalten und nachverfolgen können. Diese Funktion ist entscheidend für die Zusammenarbeit und das Aufrechterhalten einer klaren Historie von Änderungen. Für ein tiefgreifendes Verständnis, wie Versionierung in Flowy funktioniert und um ihr volles Potenzial zu nutzen, beziehen Sie sich bitte auf die detaillierte Dokumentation, die auf unserer separaten Seite verfügbar ist: Versionierung in Flowy.